
Java multithreading improves performance, but in large organizations it can also amplify failures unless it is governed like any other high-risk capability.
- Teams reach for multithreading under latency, cost, and delivery pressure, often as a substitute for structural change.
- Concurrency risk grows non-linearly when teams "roll their own" thread pools and patterns across services.
- Leaders should learn the signals of concurrency-driven incidents.
- Use a consistent playbook to spot, stabilize, instrument, classify, fix, and standardize.
Why Java Multithreading Fails Differently at Scale
Java-heavy engineering organizations put Java multithreading bugs in a class of their own because they bring down systems faster, defy diagnosis longer, and resist resolution more stubbornly than any other kind of defect. Leaders don't need to understand the mechanics of Java multithreading to solve these problems. Instead, they need to govern when and how to apply multithreading that meets organizational demands without creating new problems.
Multithreading is a force multiplier for both performance and failures. Problems emerge through the combined weight of concurrency design decisions applied without oversight. The larger the organization, the more this weight causes the risk of failures to increase in a non-linear fashion.
Your leadership contribution is to work with the architects to establish guidelines for all teams to follow. The decision matrix you build includes measures that lead to predictability, risk reduction, and early detection. This governance is not only preventative, it's also diagnostic.
How Organization Pressures Drive Multithreading Use
Your IT department is under constant pressure to go faster, cost less, and deliver more. In most cases, your only short-term alternative is to apply some kind of optimization to address specific pain points. Concurrency is one type of optimization your teams can apply, but it comes with a different kind of risk.
- Restructuring to improved architecture: Wholesale changes risk losing business rules built across the life of the original architecture. Success can be assured by existing regression tests to make sure features still work.
- Optimizing with concurrency: Optimizing a familiar architecture risks unpredictable behavior changes. Existing regression tests may not trigger these behaviors, so they only emerge in production, usually under heavy loads.
| Organizational pressure | What leaders are responding to | Typical multithreading response | Hidden risk introduced |
|---|---|---|---|
| Latency pressure at scale | SLAs slipping as traffic, dependencies, and request paths grow | Parallelizing work inside a service to reduce end-to-end response time | Increased contention, unpredictable tail latency, and failures that only appear under peak load |
| Cost pressure | Underutilized CPU cores and rising infrastructure spend | Increasing thread counts to do more work per deployed service instance | CPU saturation, context-switching overhead, and harder-to-predict capacity limits |
| Product pressure for async behavior | Features that require background work, side effects, or long-running tasks | Spawning background threads or using internal executors instead of decoupled workflows | Silent failures, lost work, and background tasks competing with user-facing traffic |
| Delivery pressure | Deadlines that favor incremental changes over architectural redesign | Localized concurrency optimizations in individual services or components | Inconsistent patterns across teams and non-linear growth in concurrency-related risk |
| Operational pressure | Pressure to "fix it quickly" during or after incidents | Adding threads or pools to relieve immediate bottlenecks | Masked root causes, deferred failures, and harder post-incident diagnosis |
You got your marching orders from the organization and you responded in a pragmatic fashion. This is good, but it should leave you asking two questions about each optimization:
- Implemented in sound fashion, or are we going to see the predicted problems?
- Stand-in for restructuring, or a band-aid that only raises the failure threshold?
Each team that independently devises its own Java multithreading solutions contributes to an organizational risk surface. Larger organizations with more teams rolling their own solutions cause the risk to increase non-linearly.
Knowing the risks causes leaders to lose sleep. It gets worse, though, when you realize that these problems are the most difficult to diagnose and fix. This is true not just because of their insidious nature, but also because thread problem diagnosis-savvy people are rare.
Why Teams Struggle with Multithreading
Seasoned professionals find threading problems challenging to diagnose, even after long practice. Younger developers face the same challenges with more disadvantages: computer science programs do not emphasize multithreading fundamentals compared to earlier times. As a result, recent graduates rarely have the ability to understand threading issues without on-the-job training.
- Implemented in sound fashion, or are we going to see the predicted problems?
- Stand-in for restructuring, or a band-aid that only raises the failure threshold?
Why did this happen? Modern platforms and libraries like Spring hide the gritty details that developers used to grapple with in custom code.
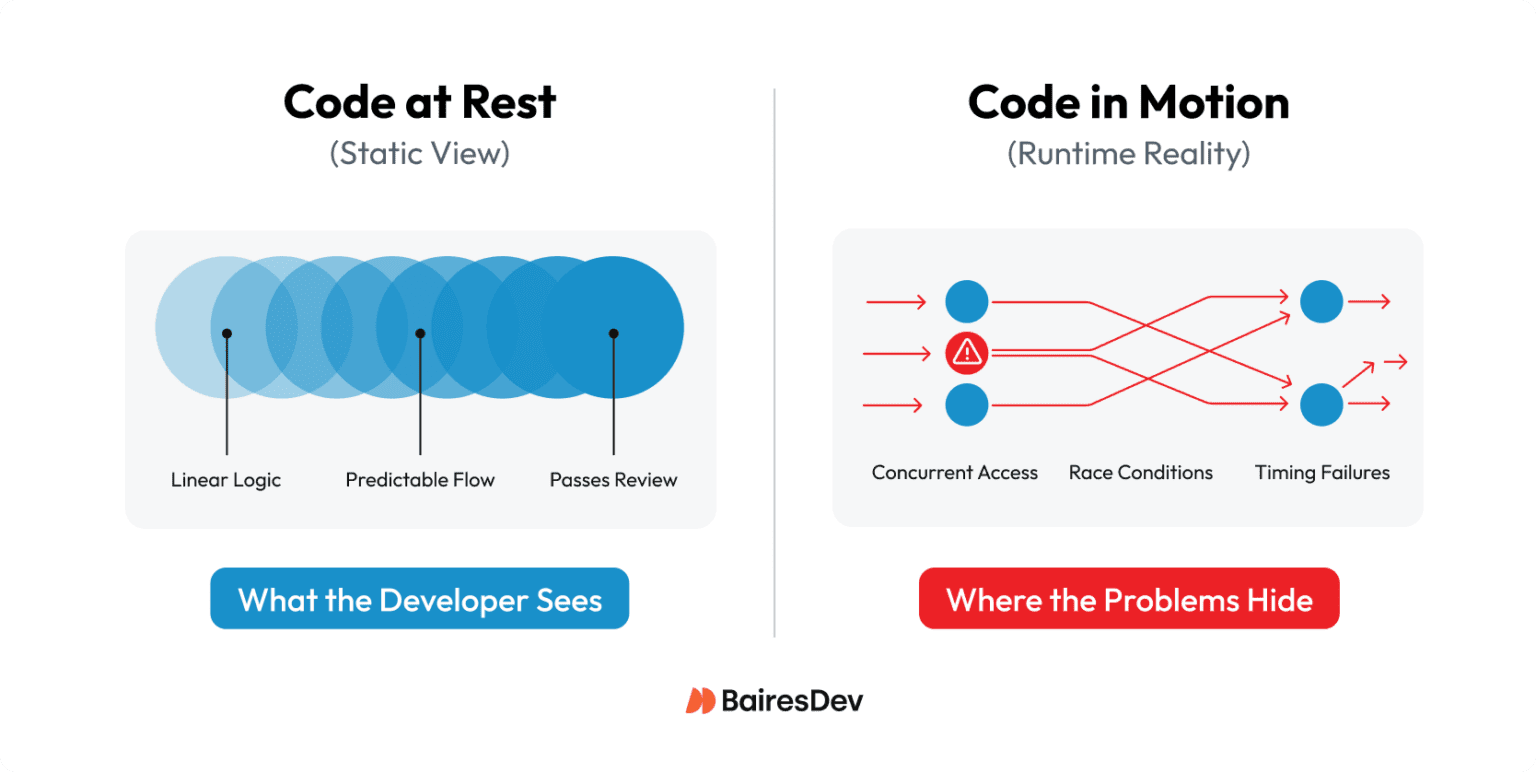
The net effect creates an organizational blind spot when multithreading problems arise. Even with an expert diagnostician, these problems are hard to find because:
- They do not appear in happy-path testing.
- Static code reviews are weak at spotting the risks.
- Incidents lack clear ownership (you'll often hear "the code is fine; it's a timing issue")
The problem is not with the Java platform. It was designed to support threading, and it has only gotten more capable with lightweight threading extensions. The root organizational problem stems from lack of architectural oversight.
As a leader, you need to involve the architects to:
- Establish guidelines for when and how to apply multithreading, including approved patterns and banned anti-patterns.
- Build a playbook for diagnosing and fixing multithreading problems when they arise.
Concurrency Risk Signals Leaders Should Recognize
Multithreading defects have problem signatures unique to their implementation. When they crop up, you may find yourself wishing for the good old days of a service showing an understandable problem. The first hallmark to look for is the sudden, large-scale flare-up.
| Leadership signal | What it indicates | Typical underlying cause | Why it matters |
|---|---|---|---|
| Unpredictable latency under load | System behavior changes non-linearly as traffic increases | Contention, blocking, or unbounded concurrency | Capacity planning becomes unreliable; SLAs fail unexpectedly |
| Throughput plateaus despite available CPU | Adding load doesn't increase useful work | Threads blocked on I/O, locks, or downstream limits | Indicates concurrency inefficiency, not lack of resources |
| Incidents that are hard to reproduce | Failures appear only in production | Timing-dependent concurrency defects | Drives long MTTR and postmortems without clear fixes |
| High variance between environments | Staging behaves nothing like production | Thread scheduling and load-sensitive behavior | Undermines confidence in testing and release gates |
| Symptoms migrate across services | "The problem keeps moving" | Stacked concurrency and load amplification | Makes ownership unclear; increases organizational drag |
| Fixes that work briefly, then regress | Short-lived stability after tuning | Masked concurrency bottlenecks | Creates false confidence and recurring incidents |
How to Diagnose and Prevent Multithreading Defects
This section contains the multithreading playbook that enables leaders to help architects and team leads: identify concurrency-driven failures early, contain their blast radius, and prevent their recurrence through governance.
Phase 1: Recognize the Failure Signature
For the recognition phase, revisit the signal table. Review each of the patterns and decide which one matches most closely the failure behavior. A multithreading defect will often involve multiple conflicting metrics or alarms — that is one tell that the failure is not from another cause. When a simpler root cause is absent, assume it's a concurrency problem.
Phase 2: Contain and Stabilize the Problem
For the containment and stabilization phase, reduce the fuel to the fire. Teams under pressure face the temptation to "change something," including the multithreading code itself. Concurrency problems respond to: (1) reducing the workload to take pressure off the failure, and (2) reducing the number of threads to make the problem more linear.
Phase 3: Build Visibility into the Multithreading Usage
Direct your architects to review the multithreading code and suggest logging and metrics to surface its specific behavior. Thread pools, consumers, and executors must be measurable. Concurrency limits must be configurable and visible. Saturation must be visible before failure happens.
Phase 4: Classify the Failure and its Hallmarks
The failure incident must get a first-class write-up including: what concurrency mechanism was implemented, how and why did it fail, how should the system respond to the root cause conditions, and what limits the architects recommend. This is how the organization learns.
Phase 5: Decide the Nature of the Long-Term Fix
This is a crucial decision point. After reviewing the case documentation and actual code, pick the final concurrency remedy: (1) Bad substitute for architectural constraint — back off the concurrency parameters. (2) Core component of service — replace with a standard solution. (3) Accidental code issue — fix it and reintroduce after sufficient load testing.
Phase 6: Prevent Recurrence through Standards
All incidents lead to the final phase. Have a set of approved concurrency patterns. Document anti-patterns that must never be followed. Establish load-testing expectations. Mandate that every concurrency implementation has an owner. Establish gateways for every future concurrency implementation. When this playbook is followed by all teams, the risk surface decreases.
Expert Perspective
I have seen organizations treat Java multithreading as a local optimization and then act surprised when incidents become harder to reproduce, harder to diagnose, and harder to permanently fix. More often than not, the problem is that concurrency decisions are made without consistent architectural guardrails.
What makes these failures expensive is the lack of a clear story. Metrics conflict, behavior changes under load, and the issue disappears when you try to reproduce it. That is why I like to start with recognition and containment: reduce load, reduce threads, and stabilize before anyone starts "tuning" code under pressure.
The turning point is visibility. If thread pools, queues, and saturation aren't measurable and configurable, you're flying blind. The most practical outcome is not perfect concurrency, but predictable concurrency — approved patterns, banned anti-patterns, load-test expectations, and a named owner for every concurrency implementation.

